
Laravel: Como visualizar a SQL com os valores preenchidos para facilitar o debug
No dia a dia do desenvolvimento com Laravel, é comum precisarmos inspecionar uma query SQL gerada dinamicamente. A primeira ferramenta... Leia mais
Desenvolvedor de Software

Ao realizar estudos de análise de dados ou ao testar sistemas que lidam com grandes volumes de informações, é comum precisarmos de dados realistas, mas fictícios, para simular cenários reais. No caso de compras, por exemplo, podemos gerar registros que envolvam pessoas, produtos, lojas, filiais e muito mais. Neste artigo, vou mostrar como gerar um milhão de registros fictícios de compras usando Python.
Para a geração dos dados, utilizaremos a biblioteca Faker, que é excelente para criar dados falsos como nomes, CPFs, datas de nascimento, e até endereços. Também utilizaremos a biblioteca csv para gravar os dados gerados em um arquivo CSV.
Os dados gerados incluirão informações detalhadas sobre:
Além disso, as compras serão distribuídas entre várias categorias de produtos (como eletrônicos, móveis e livros) e realizadas em diferentes lojas, cada uma com suas filiais em várias cidades.
Abaixo está o código completo que gera um milhão de registros fictícios de compras e salva os dados em um arquivo CSV.
Obs: Lembre-se de instalar a biblioteca FAKER através do comando pip install faker
import csv
import random
from faker import Faker
from datetime import datetime
# Inicializa o Faker para gerar dados em português do Brasil
fake = Faker('pt_BR')
# Defina a quantidade total de pessoas e compras que deseja gerar
quantidade_pessoas = 1000000 # 1 milhão de pessoas
quantidade_compras_por_pessoa = (1, 10) # Compras entre 1 e 10 por pessoa
# Nome do arquivo CSV
nome_arquivo = 'dados_compras_massivo.csv'
# Campos que estarão no CSV
campos = ['id_pessoa', 'nome', 'cpf', 'data_nascimento', 'produto', 'marca', 'categoria', 'valor', 'data_compra', 'loja', 'filial', 'cidade', 'supervisor']
# Lista de produtos, categorias e marcas
produtos_categorias_marcas = {
'Eletrônicos': [
('Notebook', ['Dell', 'HP', 'Lenovo', 'Apple']),
('Smartphone', ['Samsung', 'Apple', 'Xiaomi', 'Motorola']),
('Monitor', ['LG', 'Samsung', 'Dell', 'AOC'])
],
'Eletrodomésticos': [
('Geladeira', ['Brastemp', 'Electrolux', 'Consul']),
('Fogão', ['Brastemp', 'Fischer', 'Atlas']),
('Microondas', ['Philco', 'Electrolux', 'LG'])
],
'Móveis': [
('Cadeira Gamer', ['ThunderX3', 'DXRacer', 'Pichau']),
('Mesa de Escritório', ['Movelnorte', 'TecnoMobili', 'Politorno'])
],
'Livros': [
('Livro Python', ['Editora Novatec', 'Alta Books']),
('Livro Machine Learning', ['O\'Reilly', 'Manning'])
],
'Roupas e Acessórios': [
('Tênis', ['Nike', 'Adidas', 'Puma']),
('Camisa', ['Zara', 'Hering', 'Riachuelo']),
('Relógio', ['Casio', 'Rolex', 'Swatch'])
]
}
# Estrutura das lojas, filiais e supervisores
lojas = {
'Loja A': {
'supervisor': fake.name(),
'filiais': {
'Filial 1': 'São Paulo',
'Filial 2': 'Rio de Janeiro',
'Filial 3': 'Curitiba'
}
},
'Loja B': {
'supervisor': fake.name(),
'filiais': {
'Filial 1': 'Belo Horizonte',
'Filial 2': 'Porto Alegre',
'Filial 3': 'Brasília'
}
},
'Loja C': {
'supervisor': fake.name(),
'filiais': {
'Filial 1': 'Salvador',
'Filial 2': 'Fortaleza',
'Filial 3': 'Recife'
}
},
'Loja D': {
'supervisor': fake.name(),
'filiais': {
'Filial 1': 'Manaus',
'Filial 2': 'Belém',
'Filial 3': 'São Luís'
}
}
}
# Função para gerar uma data de compra aleatória entre 01/01/2020 e a data atual
def gerar_data_compra():
data_inicio = datetime(2020, 1, 1) # Data de início das compras
data_fim = datetime.now() # Data atual
return fake.date_between_dates(date_start=data_inicio, date_end=data_fim).strftime("%d/%m/%Y")
# Função para gerar dados de uma pessoa com suas compras
def gerar_compras_pessoa(id_pessoa):
nome = fake.name()
cpf = fake.cpf()
data_nascimento = fake.date_of_birth().strftime("%d/%m/%Y")
# O número de categorias não pode ser maior que o total de categorias disponíveis
numero_compras = random.randint(1, min(quantidade_compras_por_pessoa[1], len(produtos_categorias_marcas)))
categorias_escolhidas = random.sample(list(produtos_categorias_marcas.keys()), numero_compras)
compras = []
for categoria in categorias_escolhidas:
produto, marcas = random.choice(produtos_categorias_marcas[categoria])
marca = random.choice(marcas)
valor = round(random.uniform(50.0, 5000.0), 2) # Valor da compra entre R$50 e R$5000
data_compra = gerar_data_compra() # Data da compra aleatória entre 2020 e hoje
# Escolha de uma loja, filial e cidade
loja_escolhida = random.choice(list(lojas.keys()))
filial_escolhida, cidade = random.choice(list(lojas[loja_escolhida]['filiais'].items()))
supervisor = lojas[loja_escolhida]['supervisor']
compras.append({
'id_pessoa': id_pessoa,
'nome': nome,
'cpf': cpf,
'data_nascimento': data_nascimento,
'produto': produto,
'marca': marca,
'categoria': categoria,
'valor': valor,
'data_compra': data_compra,
'loja': loja_escolhida,
'filial': filial_escolhida,
'cidade': cidade,
'supervisor': supervisor
})
return compras
# Gera o arquivo CSV em blocos para evitar consumo excessivo de memória
bloco = 10000 # Número de registros a serem processados por vez
with open(nome_arquivo, mode='w', newline='', encoding='utf-8-sig') as arquivo_csv:
escritor_csv = csv.DictWriter(arquivo_csv, fieldnames=campos)
escritor_csv.writeheader() # Escreve o cabeçalho
id_pessoa = 1
while id_pessoa <= quantidade_pessoas:
compras_bloco = []
for _ in range(bloco):
if id_pessoa > quantidade_pessoas:
break
compras = gerar_compras_pessoa(id_pessoa)
compras_bloco.extend(compras)
id_pessoa += 1
# Escreve o bloco de dados no arquivo
escritor_csv.writerows(compras_bloco)
print(f'Dados de {quantidade_pessoas} pessoas e suas compras foram gerados e salvos no arquivo {nome_arquivo}.')
Gerar um milhão de registros pode consumir muita memória. Para contornar isso, o código acima divide o processamento em blocos de 10 mil registros, escrevendo os dados diretamente no arquivo CSV em blocos. Dessa forma, evitamos manter todos os dados na memória ao mesmo tempo.
Com esse script, conseguimos gerar rapidamente uma grande quantidade de dados fictícios de compras, distribuídos entre diferentes lojas, filiais, produtos e categorias. Esses dados podem ser utilizados para testes de performance de sistemas, criação de gráficos de análise ou aprendizado em análise de dados.
Agora você pode adaptar esse código para gerar dados que atendam às suas necessidades, seja para um volume menor ou para cenários mais complexos.
No dia a dia do desenvolvimento com Laravel, é comum precisarmos inspecionar uma query SQL gerada dinamicamente. A primeira ferramenta... Leia mais
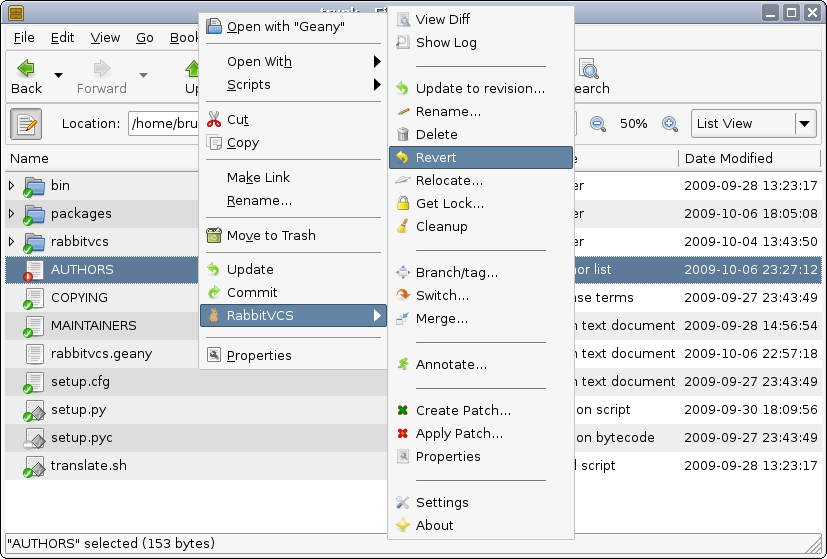
Caso você sendo usuário Linux e precise instalar um gerenciador de SVN temos como alternativa o RABBITVCS. São apenas dois... Leia mais

À medida que um sistema cresce, a lógica de negócio costuma se tornar mais complexa. Um dia você está apenas... Leia mais

A robótica e a eletrônica são áreas fascinantes que combinam criatividade e lógica para construir soluções incríveis. Hoje, vamos explorar... Leia mais